Recently we got a test server with PCI-e SSD from INTEL-P3600 1.2TB.
Operating system see it as: INTEL SSDPEDME012T4
[root@c1701 vector]# isdct show -nvmelog smarthealthinfo
- SMART and Health Information CVMD550300L81P2CGN -
Available Spare Normalized percentage of the remaining spare capacity available : 100
Available Spare Threshold Percentage : 10
Available Spare Space has fallen below the threshold : False
Controller Busy Time : 0x19
Critical Warnings : 0
Data Units Read : 0x380EC1
Data Units Written : 0xC0C8D4
Host Read Commands : 0x031AA3A3
Host Write Commands : 0x08B44DE8
Media Errors : 0x0
Number of Error Info Log Entries : 0x0
Percentage Used : 0
Power Cycles : 0x10
Power On Hours : 0x01FD
Media is in a read-only mode : False
Device reliability has degraded : False
Temperature - Celsius : 35
Temperature has exceeded a critical threshold : False
Unsafe Shutdowns : 0x08
Volatile memory backup device has failed : False
Now the question is rising: Do we need at all PCI-e NVMe SSD? How we can use it to boost any of our daily used systems??
The bad thing with PCI-e is usability, if it starts to fail one need to turn off the BOX to replace it. For the time critical systems it is unacceptable. One can think well do some kind of HA pairs of boxes. But any HA layer adds its failure probability and for sure dumps down you HW performance.
As a first touch test I just started to check the Robinhood scans of the lustre fs.
This process runs as a daily cron job on the dedicated client.
Here is the benchmarks with recent "Lustre client" hardware:
Aim: to keep lustrefs file tables in mysql InnoDB.
===========================================
Robinhood 3 with CentOS7.3 and lustrefs 2.9 client
Lustre server 2.9 CentOS6.8,4x4mirrored Intel SSD MDS,
3Jbods-18 OSTS(450-600MB/s per OST),3xMR9271-8i per ost,24 disk per OST, Interconnect FDR 56Gbit,
with MPI tests up to >3.5GB/s random IO
Currently used: 129TB out of 200TB, no striped datasets.
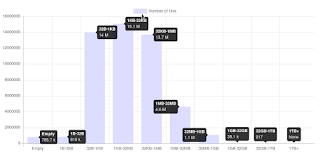 |
| Data distribution histogram: Files count/Size |
time lfs find /llust -type f | wc -l
[root@c1701 ~]# time lfs find /llust -type f | wc -l
23i935507
real 11m13.261s
user 0m12.464s
sys 2m15.665s
[root@c1701 ~]# time lfs find /llust -type d | wc -l
776191
real 6m40.706s
user 0m3.500s
sys 0m56.831s
[root@c1701 ~]# time lfs find /llust | wc -l
24888641
real 3m52.773s
user 0m10.867s
sys 1m4.731s
The bottleneck is probably MDS, but it is fast enough to feed our InnoDB with files stats and locations.
===========================================
Final robinhood InnoDB database size is about ~100GB
Engine InnoDB from Oracle MySQL: mysql-5.7.15-linux-glibc2.5-x86_64 (Why not MariaDB? there are some deviations with mariadb. It is a little bit slower than OMySQL +/- 5/10%. But for the final test conclusions this is not so relevant)
my.cnf
innodb_buffer_pool_size=40G
tmp_table_size=512M
max_heap_table_size=512M
innodb_buffer_pool_instances=64
innodb_flush_log_at_trx_commit=2
==================================
we setup here RAIDZ2 8x3TB HGST HUS724030ALA640 with LSI-9300-8i in IT mode.
FS setup for the tests:
- zpool create tank raidz2 /dev/sda /dev/sdb /dev/sdc /dev/sdd /dev/sde /dev/sdf /dev/sdg /dev/sdh -f
- zfs set compression=lz4 tank
- zpool create nvtank /dev/nvme0n1
- zfs set compression=lz4 nvtank
- mkfs.xfs -Lnvtank /dev/nvme0n1 -f
Results of mytop query per second-qps:
- 8xRAIDZ2 compression none qps: ~98 burst up to 300
- 8xRAIDZ2 compression lz4 qps: ~107 burst up to 480
- nvmeZFS compression none qps: 5000 burst up to 12000
- nvme XFS qps: ~17000 burst up to 18000
First results are showing thath XFS wins against ZFS. The latency of the PCI-e impressive, but once you add any software raid on it like ZFS, compression, its becoming slow but not as slow as 8xSpinning disks.
